主要功能是信息储存可比喻为蓝图或配方。
简称DNA它是一种生物大分子,可组成遗传指令,引导生物发育与生命机能运作。其中包含的指令,是建构细胞内其他的化合物,如蛋白质与核糖核酸所需。带有蛋白质编码的DNA片段称为基因。其他的DNA序列,有些直接以本身构造发挥作用,有些则参与调控遗传信息的表现。
DNA是一种由核苷酸重复排列组成的长链聚合物,宽度约22到24埃(2.2到2.4纳米),每一个单位则大约长3.3埃(0.33纳米)。在整个脱氧核糖核酸聚合物中,可能含有数百万个相连的核苷酸。例如人类细胞中最大的1号染色体中,就有2亿2千万个碱基对。通常在生物体内,脱氧核糖核酸并非单一分子,而是形成两条互相配对并紧密结合,且如藤蔓般地缠绕成双螺旋结构的分子。每个核苷酸分子的其中一部分会相互连结,组成长链骨架;另一部分称为碱基,可使成对的两条脱氧核糖核酸相互结合。所谓核苷酸,是指一个核苷加上一个或多个磷核苷则是指一个碱基加上一个糖类分子。

DNA和RNA的组成与结构。左为RNA,右为DNA。
人类基因组中蕴含了丰富的遗传信息, 当前法医DNA常规使用的短串联重复序列(short tandem repeat, STR)遗传标记只运用了基因组中与个体识别相关的少量信息, 基因组中还有大量与人的外观表型等相关的遗传信息尚未用于法医实践。同时, 当前法医DNA技术的作用更多体现在“ 比对人” , 而实际侦查工作中对嫌疑人的刻画需求也非常迫切, 而现有技术无法提供族群地域、年龄、身高、外貌等特征信息, 难以实现“ 刻画人” , 当现场DNA与嫌疑人或数据库都无比中时, 案件侦查容易陷入被动或停滞。如何通过DNA检验为案件侦破和嫌疑人搜查提供更多信息, 是目前法庭科学领域研究的重心之一。人类外观特征, 特别是面部形态特征, 虽为复杂性状, 但具有高度的遗传保守性。面部刻画作为物证刻画的核心信息之一, 由于其易于辨识, 往往成为侦查搜索时最直接的一种线索。所以, 如何用DNA作为画笔, 对犯罪嫌疑人的表型特征进行刻画, 成为了目前法庭科学领域的研究热点。
目前, 用DNA技术进行表型特征刻画主要基于第三代遗传标记— — 单核苷酸多态性位点(single nucleotide polymorphisms, SNPs)来进行。SNPs位点广泛分布在基因组的编码区和非编码区, 蕴含大量与人的种族地域、身高、面貌、色素等表型特征等相关的信息。伴随高通量芯片、测序等就技术发展, 研究者们通过全基因组关联分析研究(genome-wide association study, GWAS)等分析策略, 挖掘到大量外貌特征相关的SNPs位点, 如头发与虹膜的颜色、皮肤色素沉淀如肤色深浅和雀斑、身高、毛发特征、面部形态特点等。然后通过研究相应的计算预测模型对未知DNA样本进行表型特征预测。在该领域的研究中, 欧洲和美国研究起步较早。荷兰科学家Kayser研制了用于推断头发和眼睛颜色的HIrisPlex系统, 该系统已经开始用于案件检验。美国ParabonNanolabs公司综合多家实验室数据结果推出了外貌特征预测软件, 并开始为执法机构提供现场物证的分子画像服务。2014年3月, 著名自然科学领域期刊《Nature》在News专栏发表了一篇题为“ 基于DNA数据建立嫌疑人面部照片” (“ Mugshots built from DNA data” )的文章, 对目前世界上三个著名的DNA分子画像实验室的最新研究进展进行了关注与讨论。荷兰Kayser实验室使用欧洲5个国家的人群的样本为基础数据, 发现了5个与面部特征形态相关的SNPs位点, 初步探索了面部整体形态的推断、建模系统。美国Shriver实验室基于每个3D面部图像的7 000个点, 结合性别、地域来源等信息, 建立了脸部预测模型。中科院上海生命科学研究院计算生物学研究所的唐鲲研究员团队为了更全面、精细地分析面部特征结构, 采用更加精细的面部3D扫描数据, 每张脸达到了30 000个数据点, 建立了一种新的全自动非刚性配准(non-rigid registration)3D面部图像测绘方法。目前, 唐鲲团队通过对欧洲人群和中国汉族人群面部特征进行差异分析, 对从地域和血缘上都属于欧亚混合人群的维吾尔族人群样本进行GWAS分析, 找出了与维吾尔族面部特征相关的SNPs位点并建立了预测模型, 该模型中加入了身高、体重、年龄等影响因素, 使得预测更加准确。
本文基于唐鲲小组筛选的350个SNPs位点和预测模型, 对18名维吾尔族男性和6名汉族男性进行了DNA分子画像, 最后对预测脸的效力和准确性进行评估。
1 材料与方法
1.1 样本来源在知情者同意原则下, 采集了18名维吾尔族男性和6名汉族男性共24名无关个体的静脉血和三维人脸图像。
1.2 DNA提取、定量静脉血通过德国QIAGEN 公司QIAamp® DNA Blood Midi试剂盒(血液)提取纯化得到DNA模板。用NanoDrop 2000c 分光光度计(Thermo Fisher Scientific公司, 美国)进行定量, 以去离子灭菌水调整浓度至5~10 ng /μ L备检。
GATK, Plink等生物信息学软件分析处理, 得到约1 500万个常见SNPs位点分析数据。
1.4 三维人脸面部图像采集及处理采用彩色手持三维扫描仪(Artec Spider, 德国)获取三维人脸原始数据。扫描顺序是从被采集人的一侧耳部开始, 上下S型经鼻面部向另一侧耳部移动, 然后向下采集下巴被遮挡部位的图像, 最后回到开始的部位完成扫描(单帧曲面范围90mm× 70mm~180mm× 140mm)。之后用三维扫描仪自带软件Artec Studio 11 Professional进行处理, 得到分析时所需数据。
1.5 人脸面部形态相关遗传位点本研究通过前期文献挖掘, 筛选收集已发表文献中, 与正常人类脸部形态相关性达到p < 5× 10-8且经重复验证后的73个SNP位点, 同时结合唐鲲等已发表用于人脸预测的277个SNPs, 共计350个遗传位点。从1.3中提取这350个遗传位点的信息。
1.6 重塑脸部三维形态本文利用的人脸遗传预测模型是建立在平均值为年龄20岁, 身体质量指数(BMI)为22的维族人群样本上。基于已测得样本的350个人脸遗传位点, 依次累加残差脸后, 合成样本个体的三维预测脸。同时, 使用中国泰州汉族人群的年龄和BMI与人脸相关性及其预测模型(数据未发表), 将上述遗传预测脸回归至样本采集时的年龄及BMI, 得到与真实脸相对应的预测脸。为鉴定遗传预测脸与实际脸的差异性是否显著小于随机情况下差异, 我们在位点基因型频率一定的情况下, 随机抽取每个位点基因型并组合, 形成随机基因型的350个人脸遗传位点后, 依据人脸遗传预测模型, 合成随机预测脸。
1.7 遗传预测脸的效力评估本文利用角度相似性和距离相似性来评估预测效力。就角度而言, 若两张脸相互独立, 其高维空间形成的角度为90度, 若为锐角, 两张脸具有一致的形态方向, 钝角则被视为相反的形态方向。预测脸和真实脸越相似, 角度形成锐角且值越小。就距离而言, 预测脸和真实脸越相似, 其点与点之间的欧氏距离越小, 形成的整体距离差异也就越小。为避免年龄和BMI引入的后天环境干扰, 我们比较了样本的遗传预测脸与真实脸之间的角度值和距离值, 统计其均值作为遗传预测能力。另一方面, 我们任意抽取等样本量的随机预测脸, 计算随机预测脸与真实脸的角度值和距离值后得其均值, 重复此任意抽样及计算过程1 000次后, 形成的1 000次随机相似性统计量均值, 便作为零假设即随机情况下的相似性分布。最后, 我们利用正态分布单边检测的P值来判断评估遗传预测脸的预测效力。
1.8 遗传预测脸在模拟场景中的准确率评估假设经办案人员侦察, 找到n个与案件相关的潜在嫌疑人, 其中有一人为真实罪犯。办案人员在现场采集到生物物证, 经DNA抽提检测获取现场物证的遗传预测脸, 将每个潜在嫌疑人的真实脸与现场物证的遗传预测脸进行角度相似性和距离相似性比较, 角度值/距离值最小者, 最有可能是现场物证的来源人。为此, 我们编制软件算法进行模拟场景识别评估, 将本研究中的待预测样本的真实脸以n=2、3、4、5的形式进行随机抽取组合, 然后选择每个组合中的任意样本的遗传预测脸与该组合的真实脸进行角度和距离计算, 预测正确的数值为1, 预测错误的数值为0。遍历所有样本组合, 重复以上识别过程, 可得到在此样本群体中的识别准确率。在随机情况下, n名个体中任意抽取一人判定为嫌疑人的准确率为1/n, 比较依靠遗传预测脸获得的识别准确率是否优于随机准确率, 可进一步判定预测模型在刑侦中的应用价值。
2 结果
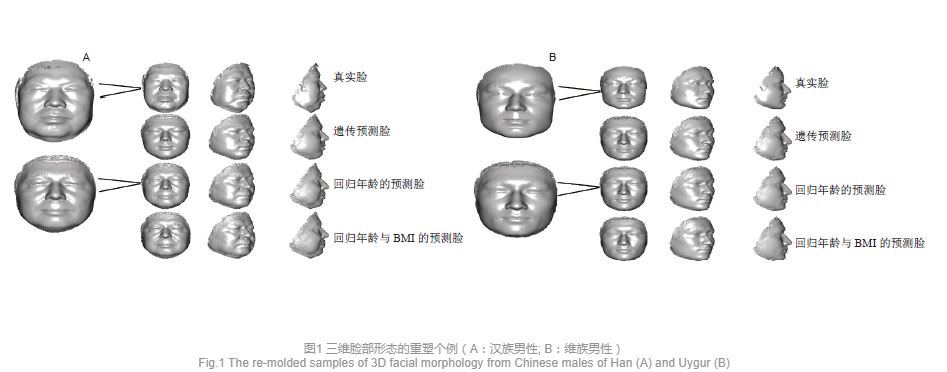
2.1 三维脸部形态的重塑在测序得知个体人脸相关遗传位点基因型的基础上, 利用人脸遗传预测模型, 合成个体年龄为20岁, BMI为22时的遗传预测脸(图1A/B, 第二行), 利用简单线性年龄的人脸预测模型, 脸部形态回归到个体自身年龄(图1A/B, 第三行), 在此基础上, 利用简单线性BMI的人脸特征预测模型, 脸部形态回归到个体相对应的BMI(图1A/B, 第四行)。图一A、B中最左侧为真实脸和回归年龄的预测脸的放大。观察图一可以看出, 通过与面貌特征相关的350个遗传位点, 基于维吾尔族人脸面部预测模型可以对面貌进行预测, 返回到三维脸部形态, 并从面貌特征上有一定的相似性。当加入年龄和BMI后天因素之后的人脸特征预测模型, 可以使预测模型更加准确, 回归年龄与BMI的预测脸更接近于真实脸。
2.2 预测效力的测定为避免年龄和BMI引入的后天环境干扰, 我们比较了样本的遗传预测脸与真实脸之间的角度值和距离值。同时为避免不同民族的相互影响, 我们将样本分为汉族和维族两个群体, 分别对其在角度相似性(图2, 第一列)和距离相似性(图2, 第二列)进行预测效力的评估。从图2可以看出, 针对汉族样本, 遗传预测脸从角度和距离两个层面, 都比随机预测脸结果要好(P值都小于0.05); 针对维族样本, 遗传预测脸从距离这一个角度, 比随机预测脸要好。
2.3 遗传预测脸在模拟场景中的预测效果评估在假定的n(n=2, 3, 5, 8, 10…)个组合中, 利用其真实脸与遗传预测脸相似性判定, 鉴别真实的样本供者, 并遍历样本获取此识别方法较随机概率在汉族男性6个样本(表1)和维族男性18个样本(表2)的准确率。通过表1和表2可以得出:1) 经过面部特征模型预测的遗传预测脸在模拟场景中的准确率普遍比随机选取的准确率要高。2) 维族男性中识别准确率比汉族男性中识别准备率在多样本中提升的更快, 原因可能是该模型是基于维族样本进行建立的, 也可能的原因是实验样本较少。3) 维族男性中识别准备率当从10个人选一个嫌疑人的预实验中, 从距离相似性的角度准备率由10 %提升到15.5 %, 提升了自身的50 %。针对人脸如此复杂的性状来说, 该模型有一定的预测和区分的能力。

3 讨论
本研究首次将DNA面部分子画像技术在法医领域进行应用。通过对检测样本全基因测序, 提取与相貌特征相关SNPs位点, 利用面貌预测模型预测, 三维脸部形态的重塑, 预测效力的测定, 遗传预测脸在刑侦模拟场景中的预实验等分析, 具有一定的预测效果, 说明DNA面部分子画像技术在刑事侦查领域的应用很有前景。由于本研究样本量较少(汉族男性6人, 维族男性18人), 在评估预测效力和识别准确率上都会损失较大的鲁棒性, 样本量的增加将有望解决这一问题。同时, 本研究男性志愿者年龄和BMI分布较广(年龄:18~57岁, BMI:17.8~29.1), 由此后天因素带来的脸部形态差异也将增大干扰成分。本研究所用遗传预测模型建立在维族样本基础上, 年龄和BMI预测模型针对汉族样本建立, 尽管预测脸给出了脸部形态的大体发展趋势, 但基于相对应民族的预测模型更能恰当准确地描述此民族个体的脸部形态发育。该技术走向成熟还有较长的一段路要走, 现阶段主要面临以下几个问题:
1) 与面部特征相关遗传位点研究缺乏。面部特征的研究复杂程度远远超过单一遗传性状, 并且与癌症和人类其他疾病的基因组学研究相比, 面部特征的研究少之又少, 政府和企业投入经费远远不足, 相关领域的实验室屈指可数, 导致目前与面部发育相关的遗传机制尚未完全清楚, 为寻找和完善面部特征相关位点增加了难度。
2) 与面部特征相关联的全基因组数据缺乏。随着测序成本越来越低, 出现了很多全基因组学数据库, 比如HapMap和1000 genomes。这些数据库记录了很多疾病、年龄、身高、体重、种族等信息。但这些样本并没有三维人脸数据, DNA面部分子画像研究无法利用如此庞大的数据库进行研究。
3) 建立预测模型的样本数太少。DNA面部分子画像的模型需要基于不同种族、不同性别建立, 本研究所用的维吾尔族模型基于270个维族人群建立, 数量较少, 位点信息、位点权重上可能存在着偏差。
4) 建立模型时考虑的因素待增加。现阶段面貌预测模型只能得到轮廓信息, 而如果想要知道肤色等更准确的面部分子画像时, 需要在建模时将其考虑进去。当然, 计算量也会大幅增加, 如何优化模型算法也将是需要考虑的问题。
总之, 本文对DNA面部分子画像进行了初步尝试, 成功通过DNA分型数据获得了样本供者的遗传预测脸, 且识别准确率优于随机准确率。未来将会加大投入, 不断增加样本数量, 找出更准确代表面部形态特征的遗传位点, 进而优化预测模型, DNA分子画像技术定会有较大的突破。
The authors have declared that no competing interests exist.
作者已声明无竞争性利益关系。